相对于Java来说,Python富有更灵活的程序设计方法,动态而且同时支持面向对象以及过程式编程。这让使用这门语言的人在写程序甚至是组织系统结构方面有很多选择。但是在另一方面来说,过多的特性也容易让人产生混淆,写代码的时候我也经常因为如何组织好这么灵活(凌乱?)的程序而烦恼,因为实现的方法是在太多了,而且也不想Java一样有比较统一的标准。
一直以来都想为博客增加“归档”功能,具体可能包括“按时间归档”、“按分类归档”、“按标签归档”等等。之前实现了一个临时性的“按标签归档”的功能,文章和标签之间是多对多关系,每次增加文章的时候对应的标签的计数器会增1,删除文章或者改变该文章标签的时候对应标签的计数器会减1,当时做的时候,Appengine对事务的支持比较弱(事实上我感觉现在也好不到哪去,呵呵),所以我还使用了一个定时任务去统计一个标签被多少文章引用过,以便保持结果的准确性。而按分类归档是很好做的,因为我设计的时候已经规定了一篇文章只能属于且必须属于一个分类下,分类自身有持久化的累计功能。
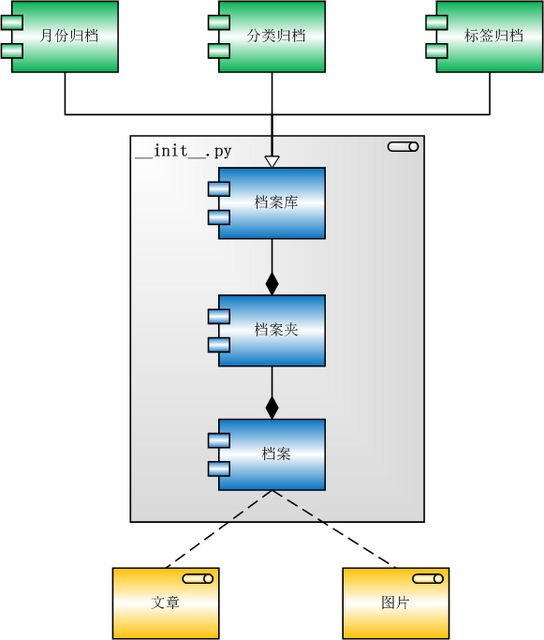
那么按时间归档改如何做呢?其实我更希望能抽象出一套统一的逻辑,以便具有良好的扩展性,能把“按标签”和“按分类”等都包容进来。从“归档”一词出发,抽取三个概念:档案、档案夹和档案库。
- 档案:被归类的实体单元,目前这就是文章,但我们也很容易把概念扩展出去,例如图片,等等。
- 档案夹:档案应该被放入的具体的类别,对于“按时间归档”来说,这就是月份,对于按标签归档来说,这是一个标签。
- 档案库:同一类档案夹所放置的地方,例如“时间档案库”是按照时间来分的,每个月一个档案夹;“分类档案库”是按照类别来区分的,每个类别一个档案夹。
于是我们得到以上三个基础名词,设计上说,这三个名词都可以成为一个抽象类,然后再各自派生出一套对象组成完整的归档模型。
结构图如下:
为了提高性能,使用memcache把结果做了缓存。(由于一个小问题,还调试了两三个晚上。把App Engine中模型中取key值的方法搞成了key了,其实应该是一个方法key(),前置直接进行了解析返回该对象,导致执行Pickle时不成功,杯具!)
如何组织安排这些代码呢?相比于C++和Java,Python在组织代码方面几乎没有什么约束,不同的人有不同的选择。一个文件内可以组织多个类,外加一些面向过程的函数、甚至是全局变量。
个人认为一种较好的方式可能是这样的:
- 面向对象和面向过程的写法可以糅合在一起,但是这些面向过程的函数应该是和处于同一文件的对象是有联系的;
- 不必局限于一个文件一个类,相同类型的类可以定义在同一个文件内;
- 公共的类定于可以放置于包的__init__.py中,例如父类,以及需要被同一个包内的其他类聚合使用的一些公共类和函数定义。
当然,怎么安排只是一种个人的习惯,本质目标只有一个:代码的条理清晰就好。